

At Gallatin, we’ve built a set of tools that lets us keep our primary repository on GitHub while automatically mirroring changes to a Palantir Foundry Code Repo. It provides automated branch protection management, tag-based release deployment, Foundry build status monitoring, a gradlew wrapper for local development, and CLI-based function execution. This makes the entire develop-test-deploy cycle UI-free for engineers and scriptable for AI coding agents.
We're building Navigator, a logistics and supply chain management platform powered by Palantir Foundry. Our backend runs almost entirely on Foundry Functions and Function-backed Actions: roughly 90% TypeScript (TSv2) and 10% Python. All served from Foundry Code Repos. We're professional software engineers shipping production code daily and require tooling that can keep up with us.
Foundry's Code Repository includes its own Git interface and pull request experience, which works well for teams whose primary workflow centers on Foundry's visual tools. Our team's workflow is different. We ship dozens of PRs weekly and rely heavily on GitHub Actions, AI-powered code review, custom test metrics, and automated alerting. We needed our CI/CD pipeline to be as configurable as the rest of our stack, and we wanted code review to feel like what it should be: a learning and knowledge-sharing activity.
Palantir builds incredible data infrastructure, and they've been an active partner as we've pushed what's possible for code-heavy teams on Foundry. GitHub has spent over a decade perfecting that exact problem space. We wanted to bring them together.
The core idea is simple: keep the primary repository on GitHub, and automatically mirror changes to a Foundry Code Repo.
But "simple" ideas often hide complex implementation details. Here's how we made it happen:
Foundry isn't just a deployment target. It's also the source of truth. When Palantir upgrades their templates (gradle.properties, SDK versions, etc.), those changes appear only in the Foundry repository. We needed true bidirectional sync:
Our solution uses GitHub Actions with a three-step sync process on every merge to master:
On Merge to GitHub master → Merge Foundry updates → Push to Foundry → Push back to GitHubFeature branches are simpler: they force-push directly to Foundry, enabling Live Preview debugging without affecting the protected master branch.
There was an immediate problem: Foundry's master branch was protected, and there's no official API to temporarily bypass protection for automated pushes. Foundry's branch protection doesn't yet support service account bypass, so we needed a workaround.
Chrome DevTools revealed the answer. Watching the network traffic while toggling branch protection in the UI exposed the internal API calls. The endpoints weren't documented, but they were discoverable. With a bit of curl extraction, the result was a GitHub Action that:
1# unprotect foundry master
2curl --request POST \
3 --url "https://${FOUNDRY_HOSTNAME}/stemma-pull-request/api/repos/${FOUNDRY_REPO_RID}/${ENCODED_BRANCH}/unprotect" \
4 --header "Authorization: Bearer ${FOUNDRY_TOKEN}"
5
6# push to foundry master
7git push palantir HEAD:refs/heads/master
8
9# protect foundry master
10curl --request POST \
11 --url "https://${FOUNDRY_HOSTNAME}/stemma-pull-request/api/repos/v2/${FOUNDRY_REPO_RID}/${ENCODED_BRANCH}/protect" \
12 --header "Authorization: Bearer ${FOUNDRY_TOKEN}" \
13 --header "Content-Type: application/json" \
14 --data '{
15 "protectedBranchOptions": {
16 "requireApproval": true,
17 "requireNoRejects": false,
18 "newCommitsInvalidateReviews": false
19 }
20 }'These APIs are undocumented and will eventually change. The risk is documented in the code, and when they break, we'll adapt.
With code syncing solved, the next step was automating deployment. The goal: merge to master on GitHub and have Foundry deploy automatically, with no manual UI steps.
In Foundry, merging a PR doesn't deploy anything. After every merge, an engineer has to manually navigate to the Code Repository UI, click "Tag version," select a version type, and wait for the release to complete.
A closer look at the UI revealed that "Tag & Release" simply creates a git tag. The question became: what happens if you push a tag directly to Foundry's repository?
It worked. Pushing a semantic version tag (e.g., 0.1.42) triggers Foundry's release pipeline automatically.
Now our workflow does this on every merge to master:
1# Get latest tag, increment patch version
2LATEST_TAG=$(git tag --list --sort=-version:refname | grep -E '^[0-9]+\.[0-9]+\.[0-9]+$' | head -n1)
3NEW_TAG="${MAJOR}.${MINOR}.$((PATCH + 1))"
4
5# Push to both remotes (gh and foundry)
6git tag -a "$NEW_TAG" -m "$COMMIT_MESSAGE"
7git push origin "$NEW_TAG"
8git push palantir "$NEW_TAG"Merge to master → automatic release to dev. No UI interaction required.
Pushing a tag triggers Foundry's release pipeline, but how do you know if the build succeeded? The GitHub workflow would happily report success while Foundry's build failed silently.
Back to Chrome DevTools. The Foundry Code Repository UI polls a GraphQL endpoint to display build status. Capturing those requests revealed the query structure, including a crucial detail: the fetch-user-agent: forge-graphql-client/0.0.0 header is required to bypass client restrictions.
Now the workflow can poll Foundry's build status after pushing a tag:
1curl -s "https://${FOUNDRY_HOSTNAME}/graphql-gateway/api/graphql?q=TagsAndReleasesTabQuery" \
2 -H "Authorization: Bearer ${FOUNDRY_TOKEN}" \
3 -H "fetch-user-agent: forge-graphql-client/0.0.0" \
4 -d '{"operationName":"TagsAndReleasesTabQuery",...}'If the Foundry build fails, the GitHub workflow fails too. No more silent failures.
Now that we have the signal of when the latest code change has been deployed, we can then chain that to our automated E2E Tests. A complete, automated, CI/CD Pipeline.
gradlew is Foundry's build and deployment tool. It handles everything: running tests, starting the local dev server, deploying functions. Without a working gradlew, there's no local development. The Palantir VSCode extension also calls it directly, so this was critical.
gradlewFoundry's gradlew script extracts the repository RID from the git remote URL:
1export ORG_GRADLE_PROJECT_repoRid=`git remote get-url origin | sed 's|.*/stemma/git/\([^/]*\).*|\1|'`This works perfectly when origin points to Foundry. But when origin is GitHub, the regex extracts garbage. Every Gradle command failed.
We couldn't modify gradlew directly because Foundry overwrites it on template upgrades. Environment variables weren't enough because the original script sets its own values. The solution required understanding Gradle's precedence rules:
System properties (-D) take precedence over environment variables.
We renamed the original script to gradlew.original and created a wrapper that:
.envGRADLE_OPTS with -D flags1#system properties override environment variables
2export GRADLE_OPTS="${GRADLE_OPTS:-} -Dorg.gradle.project.repoRid=${ORG_GRADLE_PROJECT_repoRid}"
3exec "$SCRIPT_DIR/gradlew.original" "$@"With this fix, ./gradlew works, the Palantir extension works, and local Live Preview works.
Once gradlew worked, we unlocked local debugging for Functions:
functions-typescript-runtimeReal debugging, with real breakpoints, against real Foundry data. No more console.log archaeology.
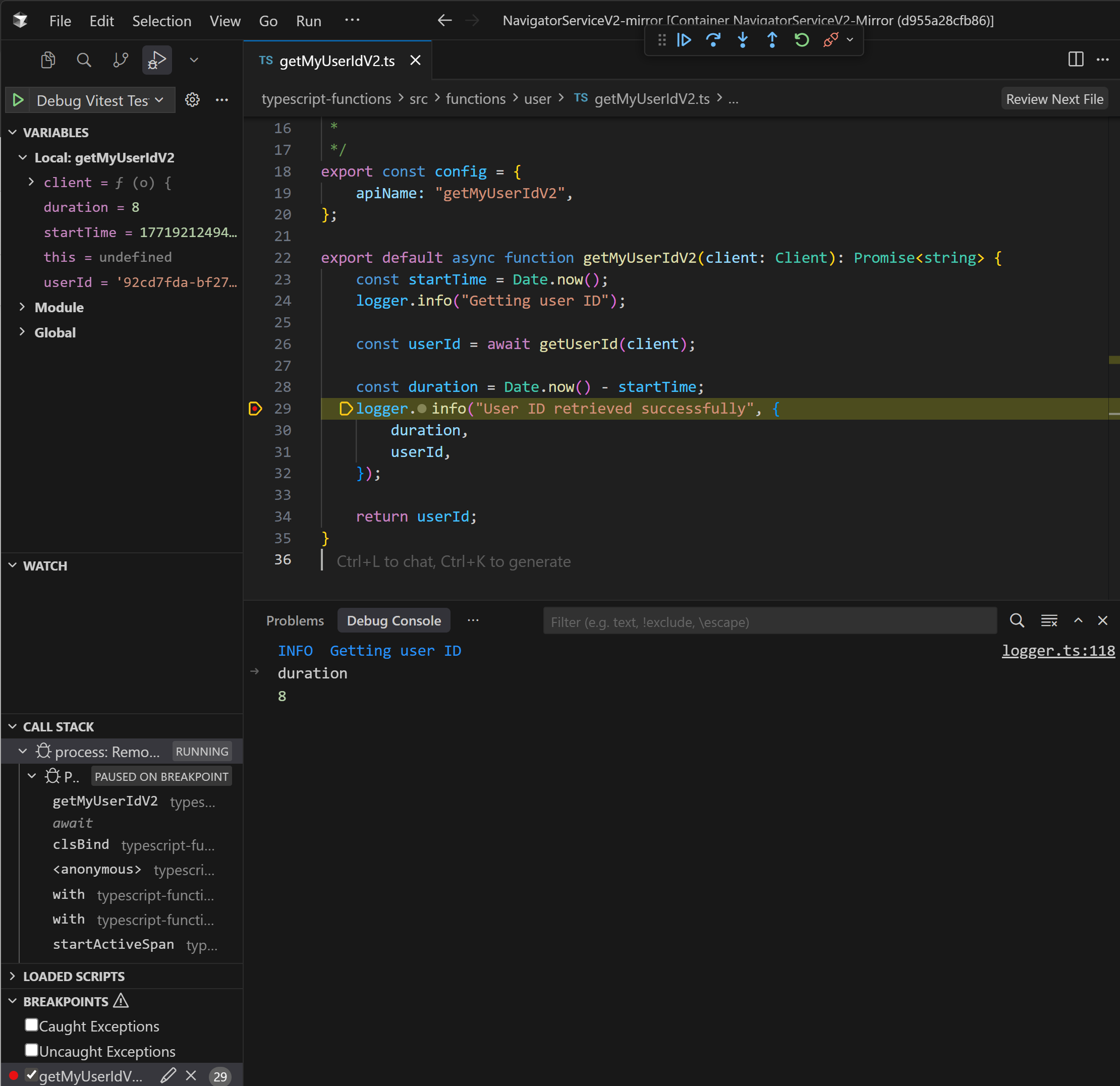
The Palantir extension worked, but function execution required UI interaction. How does it actually work behind the scenes? Enabling the palantir.networkRequestLogging.enabled flag revealed that the extension calls an undocumented ./gradlew startDevServer command, then communicates with it over HTTPS. Dissecting the logs exposed the request format, parameter encoding, and response structure. The result: run-function.sh.
1# Execute functions from the command line
2./scripts/run-function.sh --list # List available functions
3./scripts/run-function.sh MyFoundryFunction # Run a function
4./scripts/run-function.sh --save MyFoundryFunction '{...}' # Save output for analysisThis script changed our development workflow fundamentally. AI coding agents (Claude, Cursor) can now test functions programmatically without any UI interaction. The entire develop-test cycle is scriptable:
1# AI agent workflow: implement, test, iterate
2npm test # Unit tests with mocks
3./scripts/run-function.sh --save MyFoundryFunction '{...}' # Integration test against live Foundry
4./scripts/run-function.sh --logs-only --from /tmp/MyFoundryFunction-*.json # Analyze if neededThe script is read-only and won't modify Foundry data. For edit functions, it returns the list of edits that would have been made, which is perfect for validation.
We've been running this setup in production for over three months across two repositories and have processed hundreds of PRs. The impact has been significant.
Pull requests became what they should be. Code review is now a learning and knowledge-sharing activity, not a fight against tooling. We have the full power of GitHub's ecosystem: AI code review, custom Actions, test metrics, and automated alerting.
Development velocity increased. Changes mirror to Foundry in ~10 seconds. Local testing is instant. The feedback loop tightened dramatically.
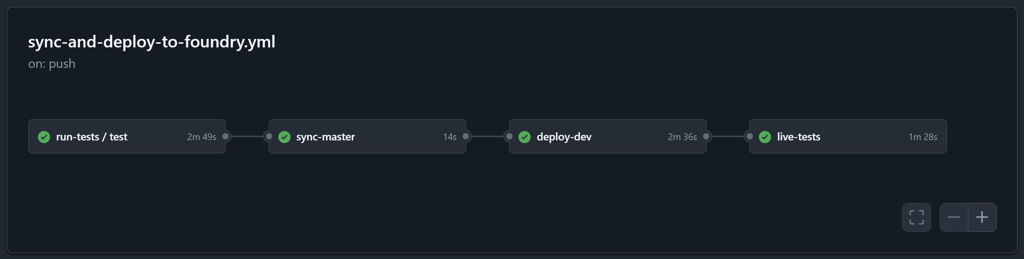
The numbers speak for themselves. Our Jira Development panel tracks PR cycle time across repositories. Over the last 30 days, we've merged 68 PRs with a median cycle time of 2.1 hours. The average is higher at 36.5 hours, pulled up by a few longer-lived feature branches, but the median tells the real story: most PRs move from open to merged in about two hours. This is the kind of velocity a GitHub-native workflow enables.
AI agents became first-class contributors. This might be the bigger win. Everything we built to get around Foundry's UI (the CLI function execution, the scriptable test cycle, the automated releases) didn't just help human engineers. It made the entire development workflow accessible to AI coding agents. Agents hate UI even more than engineers do. They can't click buttons, navigate web interfaces, or wait for Live Preview panels. But they can run shell commands. With run-function.sh, agents like Claude and Cursor can now implement a function, run the unit tests, execute it against live Foundry data, analyze the results, and iterate, all without a single UI interaction. The develop-test cycle that used to require constant human shepherding is now fully autonomous.
This setup works well for us today, but it sits on a few edges that need active care:
Undocumented APIs. The branch protection and build monitoring use internal Foundry APIs that could change without notice. We've documented these clearly and designed for graceful degradation, and can quickly update if endpoints do change.
Operational complexity. Maintaining a bidirectional sync, two protected branches, and a wrapped gradlew is real overhead. It's worth it for our team's pace, but it isn't free.
Foundry-specific resources. Object types, link types, and other ontology resources are still authored in Foundry, then pulled into our SDK via the UI. Bringing those into a code-first workflow is a natural next frontier, and it’s already in progress.
None of these are problems we're solving alone. Working through these edges has been one of the unexpected wins of the project: a real partnership with Palantir, whose team has been an excellent thought partner and is actively shaping the pro-code developer experience. The capabilities we hacked our way into are exactly the kind of features the platform is moving toward natively, and we're glad to be part of that conversation.
Developer experience matters. Good tooling multiplies velocity and scriptable tooling takes it further. AI agents move at a pace no human can match, and we wanted our workflow to keep up.
We built this because we needed it, for our engineers and for the AI agents that are increasingly part of how we ship code. The bigger story isn't the setup itself, it's the value of partnering closely with Palantir to push the ecosystem toward better developer tooling for humans and agents alike.
We're building hard things at Gallatin. This post is a small example of how we approach problems: identify friction, understand the system deeply, build tools that make the team more productive. If you’re inspired by this, come join us!
Josh Bouganim is a Senior Software Engineer leading our Foundry Backend and Infrastructure at Gallatin AI.


